
The workflow for using the OnScale Cloud tool:
- Create an input deck (.flxinp file and associated files in a single directory) via:
- Designer mode (CAD Import method)
- Analyst mode (scripting)
- Verify or preview the model using the Preview Flex model feature:
- Executes model plotting
- Performs syntax checks
- Report model errors to Console
- Launch Cloud Scheduler from the Tools tab in the Ribbon
- Hit Run on Cloud if the input deck is active in the editor or designer project open
- The Job Name will auto-populate with the name of the job file
- Users can modify the name of job as required
- A folder with this job name will be generated to store the outputs from the simulation
- Select model file to be submitted (if not already submitted)
- All supporting files will also be automatically located and submitted to the cloud
- These can be added in manually should the auto-detection algorithm fail to capture these
- Parametric Sweep will become available if the parametric variable (symbx) is detected in the input deck
- If no symbx variables are defined, the cloud scheduler will not show the Parametric Sweep options
- Click Estimate to determine the predicted time and cost of the simulation job
- Job Metrics will be shown to user
- Configure Cloud node settings by selecting the desired CPU configuration
- Advanced options available
- Click Run to execute simulation(s) on the Cloud
- On Completion, results can be accessed in the Cloud Storage window
- Results can be downloaded for post processing locally
Setting up the Cloud Scheduler
The Cloud Scheduler Tool can be accessed with the Cloud Scheduler icon or the Run on Cloud icon:

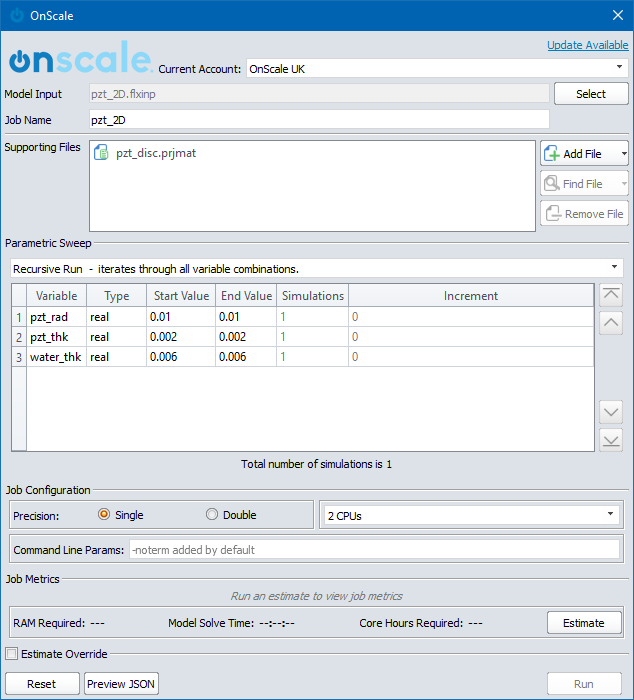
The available settings are as follow:
- Job Name – Enter unique name for the job
- Model Input – Select the input file for the job (.flxinp)
- Supporting Files – Any other files that are required by the model will be added to the job automatically
- CPU Configuration – Select the Compute Power required for Job
-
- This is the number of Cores per Compute Node. More cores can reduce the time to execute a single simulation, but may use more Core Hours
- OnScale allows CPU options of up to 64 compute cores
- Advanced Settings
-
- Precision - Sets the executable precision for simulation (Double precision offers greater numerical precision but will use double the memory and take longer to run).
- Double Precision allows access to +8GB of memory allowing larger models to be executed
- Max Core Allowance - sets a Core Hour limit which simulation job can not exceed
Running Parametric Sweeps
The Parametric Sweep options will expand the Cloud Setup to allow definition of the variables used in the parametric study.
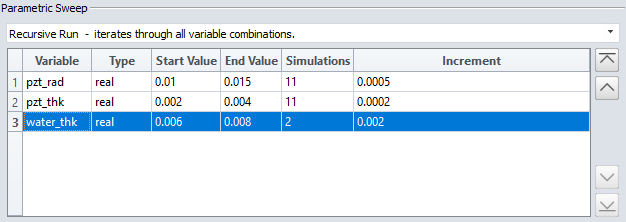
Any variable declared with symbx in the selected model file (.flxinp) will automatically appear here and allow you sweep through a range of values.
Parametric variables can be:
- Activated and deactivated using the checkbox in the Variable column
- Set a Start Value for the sweep (use largest value and sweep down)
- Set a Stop Value for the sweep
- Set the number of steps/increments from Start to Stop
Double click on relevant table cells to modify values.
The order of variables can be re-defined using the arrows at the side of the table. Select the variable to move and click on the directions to shift the variable up and down the table.
There are 3 methods of sweeping through parameters that can be selected from the drop down menu:
- Recursive Run iterates through all variable combinations, in the same way as nested for loops would change each variable. The total number of simulations is the product of the number of steps for each variable.
- Sequential Run iterates through values for each variable in turn, where the total number of simulations is the sum of the number of steps for each variable.
- User Defined Variable File iterates through the variable values as defined in a custom Comma-separated values (.csv) file.
Estimate & Run
OnScale will intelligently estimate the RAM, Core Hour and Run Time required for the simulation job. To run the OnScale Estimate, click on the Estimate button.
Once the estimation completes and is suitable, users can alter the CPU Configuration for the Job and proceed with the simulations with the Run button.
Important Estimation Notes
- All jobs must be estimated prior to running
- Note that the estimates are not exact - jobs may take less or more time dependant on the local hardware
- Estimates are run locally and use a single core to estimate the single core performance on the cloud
- Estimates are based on initial loaded variables values and do not account for model size variations due to parametric sweep
- Single or Double Precision can be used for Estimates. Single Precision is selected by default.
- Review and Build files will not be estimated and can be run immediately
- For initial OnScale versions, the estimate will be restricted by the memory available on the local machine. For large models, where you have insufficient RAM to perform the estimation, users will be allowed to manually define the RAM requirements for the model.
Simulation Execution
When the job is running, the Job Status window will appear showing all the simulation requests:
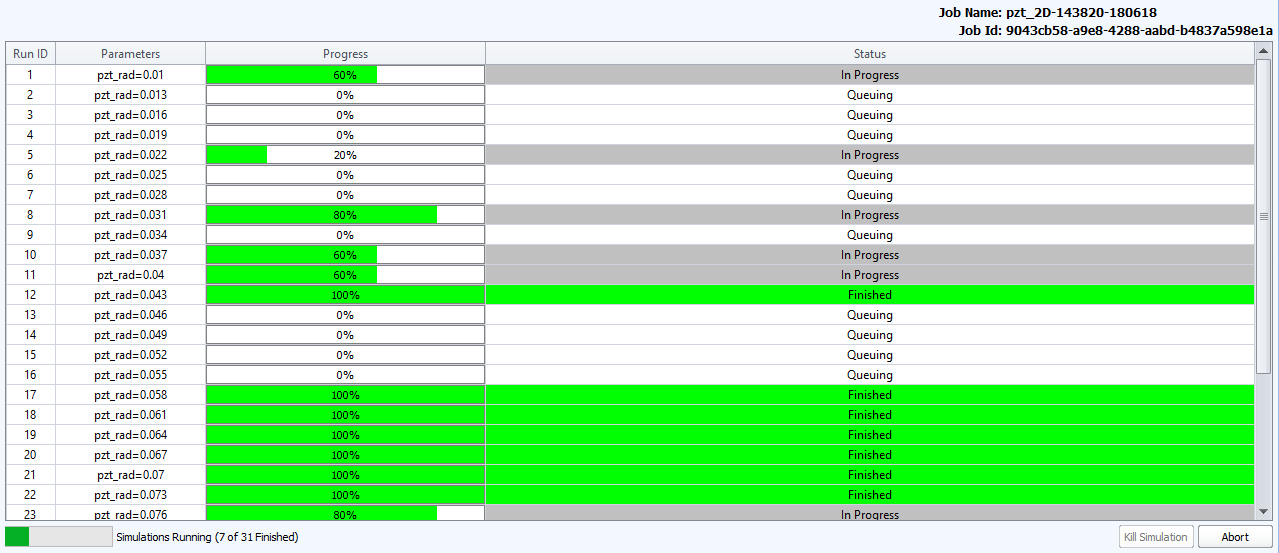
Within the Job Status table, each simulation is given an ID number, the parametric variable definition, a progress bar and simulation status.
The Job Status types that can appear are:
- Waiting for Instance - waiting for resources to become free on the cloud
- Starting - spooling up the cloud node for simulation
- Running - simulation executing
- Finished - simulation completed
- Aborted - simulated aborted
- Failed - simulation failed due to error
Jobs can be ended with the two action buttons at the bottom of the Job Status window:
- Kill Simulation can be used to kill a single or multiple running job instances. Select desired instance and click Kill Instance
- Abort can be used to kill the full cloud simulation study.
The Job Name and Job ID are highlighted at the top of the Job Status table.
Note: If you ever experience issues with a particular simulation job, quote the Job ID to the engineer